由于经常需要跟命令行和文本处理打交道,也确实在实际使用中体会到了 AWK 的强大力量,决定系统学习一下 AWK,此之为学习使用的笔记整理
Table of contents
下文中引用部分若无标注,均引用自《The AWK Programming Language》,优先阅读 Chapter 1&2&8
An awk program is a sequence of patterns and actions that tell what to look for in the input data and what to do when it’s found. Awk searches a set of files for lines matched by any of the patterns; when a matching line is found, the corresponding action is performed. A pattern can select lines by combinations of regular expressions and comparison operations on strings, numbers, fields, variables, and array elements. Actions may perform arbitrary processing on selected lines; the action language looks like C but there are no declarations (不需要声明), and strings and numbers are built-in types.
Break the job into separate pieces, and apply the most appropriate tool to each piece. => 不要因为学习了 AWK,就看到一个文本处理就使用 AWK;应该考虑实用性,对文本流进行编辑可以使用 sed,对数据进行查找可以使用 grep,排序使用 sort
AWK 语言是一种 UNIX 备用工具,它是一种功能强大的文本处理和模式匹配语言,所以它通常被称为数据驱动的语言,而不是程序操作步骤的序列。另外,AWK 常常在命令行中使用或与管道一起使用。
AWK 程序在其输入数据中搜索包含特定模式的记录、对该记录执行指定的操作,直到程序到达输入的末尾。AWK 是一种解释性语言,通常不需要编译,在运行时将程序脚本传递给 AWK 解释器。
AWK 基本内容:
- 格式化输出
- 记录
- 字段操作
- 规则
- 模式匹配
- 关联数组
- 自定义 AWK 程序
- 使用 UNIX 命令行执行复杂的文本处理
参考资料
- GAWK 入门:AWK 语言基础 讲的很不错,本文内容大部分摘抄于此
- The AWK Programming Language 豆瓣上这本书的评价很高,值得一看
The simplest awk program is a sequence of pattern-action statements:
pattern { action }
pattern { action }
...
In some statements, the pattern may be missing; in others, the action and its enclosing brace may be missing. After awk has checked your program to make sure there are no syntactic errors, it reads the input a line at a time, and for each line, evaluates the patterns in order. For each pattern that matches the current input line, it executes the associated action. A missing pattern matches every input line, so every action with no pattern is performed at each line. A pattern-action statement consisting only of a pattern prints each line matched by the pattern.
输入文件
AWK 针对文本(文件或者标准输入流)进行操作以得到记录和字段
- 记录(Record):单个的、连续长度的输入数据,是 AWK 的操作对象
- 记录分隔符(Record Separator):一个字符串,定义为 RS 变量,以分隔记录(Records)。在缺省情况下,RS 的值设置为换行符,因此 AWK 默认将每一行输入作为记录
连续地读取输入,直到到达输入的末尾
- 字段(Field):将记录进一步分解为单独的块
- 字段分隔符(Field Separator):用于限定字段(Fields),定义为 FS 变量。在缺省情况下,FS 的值设置为任意数量的空白字符,包括制表符和空格字符。因此 AWK 默认将输入行进一步分解为单独的单词(由空白字符分隔的任意字符组)
- 字段编号:可以使用字段编号引用记录中的字段,从 1 开始索引(
$1、$2、...、$NF)。对于记录的最后一个字段,可以使用索引编号,或特殊变量 NF 来调用,NF 变量包含当前记录中字段的个数 - 使用字段编号
$0引用整个记录,包括该条记录所有的字段和字段分隔符。这是许多命令的缺省参数,例如print,等价于print $0,这两个命令都将打印出当前整个记录
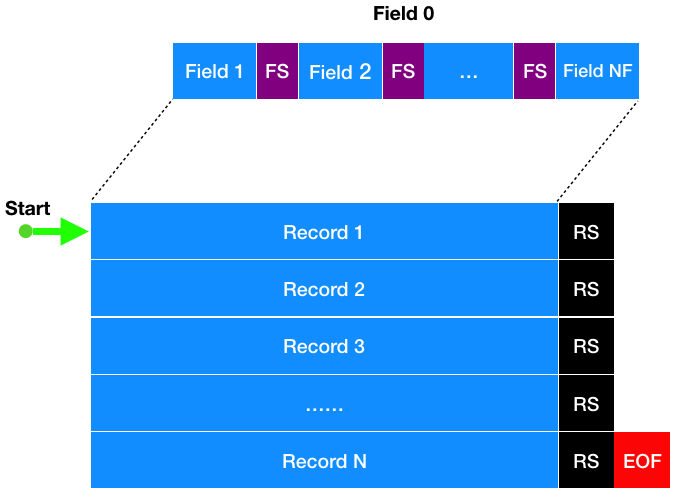
当 GAWK 读入一个记录时,它会将该记录中所有的字段存储到变量中,可以通过 $加上字段编号 来引用每个字段
规则
AWK 程序由规则组成,它们是一些模式,后面跟着由换行分隔的操作。当 AWK 执行一条规则时,它在输入记录中搜索给定模式的匹配项,然后对这些记录执行给定的操作。
/pattern/ { action }
- 模式和操作均可以省略
- 操作由 AWK 语句组成,使用分号(
;)进行分隔 - 在同一行内容中提供多个规则,必须使用分号(
;)进行分隔,例如在命令行中使用 - 当规则中仅包含一项操作时,将对输入中的每条记录执行该操作
- 当规则中仅包含一个模式时,将打印出匹配到该模式的所有记录
- 空模式
//匹配空字符,等价于规则中不包含任何模式,表示匹配所有记录 - 空操作
{}表示不进行任何操作(不打印该记录),不等价于没有任何操作(因为 AWK 只有模式没有操作时是打印匹配到该模式的所有记录)

特殊模式:BEGIN 和 END
BEGIN 和 END 不会匹配任何输入记录
BEGIN模式指定了在处理任何记录之前需要执行的操作(预处理),通常用于设置变量,例如改变字段分隔符FS的值
BEGIN { action }
END模式指定在处理了所有记录之后需要执行的操作(后处理),通常用于对从输入记录中读取的数据和图表进行制表、汇总和处理
END { action }
表达式作为模式
-
string —— 0 或多个字符组成的字符串,可以存储在变量中,也可以表示为字符串常量
- null string
- substring
-
number
Any expression can be used as an operand of any operator.
假如操作符需要一个字符串(string),但表示式求值之后的类型为数字(numeric),这个数字会自动转型为字符串类型;同样地,当操作符需要一个数字类型(numeric)时,字符串也会自动转型为数字类型
Any expression can be used as a pattern. If an expression used as a pattern has a nonzero or nonnull value at the current input line, then the pattern matches that line.
有点类似于 C 语言的条件表达式,数字和字符串都支持比较操作。如果操作符两侧都是数字类型(numeric,存储为浮点数 floating-point,精度依赖具体机器),执行数字类型的比较;如果操作符两侧不全是数字类型(有字符串),则数字类型会自动转型为字符串,执行字符串的比较。
A variable has a value that is a string or a number or both. Since the type of a variable is not declared, awk infers the type from context. When necessary, awk will convert a string value into a numeric one, or vice versa.
Uninitialized variable are created with the string value "" (the null string) and the numeric value 0. Nonexistent fields and fields that are explicitly null have only the string value “"; they are not numeric, but when coerced to numbers they acquire the numeric value 0.
有两种常见的做法来进行转型:
number "" # 拼接 null 字符串,将一个数字转型为字符串
# The string value of a number is computed by formatting the number with
# the output format conversion `OFMT`, the default value of `OFMT` is "%.6g".
string + 0 # 字符串加上 0,将一个字符串转型为数字
# The numeric value of a string is the value of the longest prefix of
# the string that looks numeric.
在进行操作(actions)同样会进行自动转型
The variables are not explicitly initialized, yet everything works properly because each variables is initialized by default to the string value "” and the numeric value 0
但有些操作符同时支持数字类型和字符串的比较,应该怎么办呢?
In contexts where the same operator applies to both numbers and strings, there are special rules. In the assignment
v = e, both the assignment and the variablevacquire the type of the expressione. In a comparision expression likex == y, if both operands have a numeric type, the comparision is numeric; otherwise, any numeric operand is coerced to a string and the comparision is made on the string values.
| 操作符(operator) | 含义(meaning) |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
= | 大于等于 > | 大于 ~ | match by !~ | not match by
正则表达式

模式匹配
- 在规则中指定模式,可以为字符串,也可以为任何扩展的正则表达式
awk '/green/ { print }' sample
awk '/!.*!/' sample
- 在特定的字段中匹配模式,可以指定该字段并使用
~操作符(表示包含),!~(表示不包含)
例如,打印那些登录 Shell 不是 bash 的所有用户的全名
awk 'BEGIN {FS=":"} $7 !~ /bash/ {print $5}' /etc/passwd
- 使用布尔操作符连接不同的模式,与(
&&),或(||),非(!) - 范围模式:在两个模式之间使用逗号,可以指定一个范围,表示匹配位于这两种模式之间和模式本身的所有文本
awk '/Heigh/,/folly/' sample
- 使用换行符作为字段分隔符,空字符串作为记录分隔符,AWK 会将整段内容作为一个记录,使其成为“段落 grep”,将输出匹配搜索的整段内容
awk 'BEGIN { FS = "\n"; RS = "" } /green/' sample
- 模式中支持比较,例如,对数字的
><>=<=的比较,对数字或字符串的==的比较
操作
Sometimes an action is very simple: a single print or assignment. Other times, it may be a sequence of several statements separated by newlines or semicolons.(一个操作中的多条语句使用换行符或分号进行分隔)

- exit —— 停止程序的执行,并且退出
- next —— 停止处理当前记录,并且前进到下一条记录
- nextfile —— 停止处理当前文件,并且前进到下一个文件
- print —— 打印使用引号括起来的文本、记录、字段和变量(缺省情况下,打印当前整个记录)。打印多个字段,在程序中使用逗号进行分隔,打印出来时是以空格分隔,
{ print $1, $3 },结尾自动打印换行符 - printf —— 打印格式化文本(与 C 语言完全一致),必须指定结尾的换行符
- sprintf —— 返回格式化文本字符串
- 可以直接使用
print $0, "xxxx"进行拼接新的 Field,也可以使用赋值运算符直接增加一个 Field,$(NF+1) = "xxxx"; print - 支持的浮点数计算包括,
+ - * / % ^
内建的字符串函数
rrepresents a regular expression (either as a string or enclosed in slashes),sandtare string expressions, andnandpare integers. The first character in a string is at position 1.(索引从 1 开始编号)

运行 AWK 程序的几种方式
- 命令行中运行
awk 'program' filename
注意:小心使用引号!AWK 中的变量,如 $1 表示字段,但在很多 Shell 中,这些字段是特殊变量,将转换为在命令行中给定的参数
- 与管道配合,作为筛选器运行:可以与 Linux 上其他命令一起
ps -ef | grep <正在运行的二进制名> | awk '{print $2}' | xargs kill -9
- 将 AWK 程序保存在
xxxx.awk文件中进行执行:使用-f选项指定程序文件
awk -f xxxx.awk filename
注意:由于 AWK 程序放在文件中,就不需要在 Shell 中使用引号将内容括起来
- 作为脚本运行:与 3 类似,需要在
xxxx.awk文件开始部分使用 shebang 命令(#!/usr/bin/awk -f),给脚本加上可执行权限chmod u+x xxxx.awk, 然后运行即可
./xxxx.awk filename
错误
AWK 的错误提示是以 >>> 和 <<< 来包围的
内置变量
all built-in variables have upper-case names.
NF—— 表示“当前记录中字段的个数”。使用NF可以引用其数值,而使用$NF则表示引用实际字段本身的内容。如果记录有 100 个字段,print NF将输出整数 100,而print $100则与print $NF输出相同的结果,都是该记录中最后一个字段的内容NR—— 表示“当前的记录个数”。当读取到第 1 个记录时,其值为 1,当读取到第 2 个记录时,其值增为 2,依此类推。使用NR表示当前读取到第几个记录,使用$NR打印当前记录对应的字段内容,例如读入第一个记录,打印第一个字段;读入第二个记录,打印第二个字段。如果有多个文件,这个值也是不断累加的
awk '{ print NR, $NR }' sample
在 END 模式中使用它,以便输出输入中的行数:
awk 'END { print "Input contains " NR " lines." }' sample
-
FNR—— 当前记录数,与NR不同的是,这个值会是各个文件自己的行号 -
FS– 字段分隔符,默认是任意个数的空格或制表符。要对整个文件使用不同的字段分隔符,可以在BEGIN中重新定义。例如,使用感叹号作为字段分隔符,打印每个记录的第一个字段
awk 'BEGIN { FS = "!" } { print $1 }' sample
注意:
1.字段分隔符可以是单个字符,也可以是字符串,甚至是任意的正则表达式
awk 'BEGIN { FS = "[Hh]eigh" } { print $2 }' sample
2.通过在命令行中使用引号将字符串括起来,并作为 -F 选项的参数,也可以更改字段分隔符
awk -F ":" ' { print $5 } ' /etc/passwd
RS—— 记录分隔符,默认为换行符,同样可以修改
awk 'BEGIN { RS = "," } { print $1 }' sample
OFS—— 输出字段分隔符,默认为单个空格ORS—— 输出记录分隔符,默认为换行符
awk 'BEGIN { ORS = "" } // { print } END { print "\n" }' sample
从文件中删除所有的换行,并将文件中所有的文本置于一行,只需 1)将输出记录分隔符更改为空字符,2)在结尾添加一个换行
FILENAME—— 该变量包含所读取的输入文件的名称IGNORECASE—— 当其设置为非空值时,GAWK 将忽略模式匹配中的大小写
用户创建的变量
In awk, user-created variables are not declared.
控制流语句

if-else
$2 > 6 { n = n + 1; pay = pay + $2 * $3 }
END {
if (n > 0) {
print n, "employees, total pay is", pay, "average pay is", pay/n
} else {
print "no employees are paid more than $6/hour"
}
}
while
# interest1 - compute compound interest
# input: amount rate years
# output: compounded value at the end of each year
{
i = 1
while (i <= $3) {
printf("\t%.2f\n", $1 * (1 + $2) ^ i)
i = i + 1
}
}
for
{
for (i = 1; i <= $3; i = i + 1) {
printf("\t%.2f\n", $1 * (1 + $2) ^ i)
}
}
数组(associative arrays)
Awk provides one-dimensional arrays for storing strings and numbers. Arrays and array elements need not be declared, nor is there any need to specify how many elements an array has. Like variables, array elements spring into existence by being mentioned; at birth, they have the numeric value
0and the string value “”.
# 将输入文件的每一行反向输出,第一行最后输出,最后一行最先输出
# 使用 while 循环
{ line[NR] = $0 }
END {
i = NR
while (i > 0) {
print line[i]
i = i -1
}
}
# 使用 for 循环
{ line[NR] = $0 }
END {
for (i = NR; i > 0; i = i - 1) {
print line[i]
}
}
for (variable in array) {
statement
}
for statement that loops over all subscripts of an array. The order in which the subscripts are considered is implementation dependent. Results are unpredictable if new elements are added to the array by statement.
自定义函数
function name(parameter-list) {
statements
# 函数中的变量的作用域与函数名绑定
}
# 当函数被调用时,函数名和参数列表的左括号之间不能出现空格
name(x, y, z) # 正确
name (x, y, z) # 错误
# 函数参数是 scalars-pass-by-value,array-pass-by-reference
- 函数参数列表中的变量是局部变量(local variables)
- 其他的变量为全局变量(global variables),整个程序的各个部分都能够访问到
环境变量
$ x=5
$ y=10
$ export y
$ echo $x $y
5 10
$ awk -v val=$x '{print $1, $2+val, $3+ENVIRON["y"]}' OFS="\t" score.txt
使用 -v 参数和 ENVIRON,使用 ENVIRON 的环境变量需要 export
注意
- AWK 输出单引号,双引号时需要转义
\"\' - AWK 与 C 语言一样,空白是为了增加可读性,没有像 Shell 一样强制要求不允许空格
好用的 AWK 命令
- 打印特定的某一行
NR == 10
- 交换两列的位置
{ temp = $1; $1 = $2; $2 = temp; print }
- 删除某一个字段
{ $2 = ""; print }
- 每一行的各个字段反向输出
{
for (i = NF; i > 0; i = i - 1) {
printf("%s ", $i)
}
printf("\n")
}
- 拆分文件,使用重定向
# 按照输入行的第六列分隔文件(`NR != 1` 表示不处理第一行)
awk `NR != 1 { print > $6 }` netstat.txt
- 按连接数查看客户端IP
netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -nr
版权声明
本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接。