Table of contents
写在最前面
侯捷老师翻译的 Effective C++,C++ 学习者人手必备一本。本系列博文是笔者在学习侯捷老师视频课程时整理的笔记,将课程内容的关键点与 Effective C++ 的对应条款做了一下联动,希望能对你有些许帮助。
- C++ 面向对象程序设计 [DONE]
- C++ 程序设计 II - 兼谈对象模型
- C++ STL 标准库 - 体系结构与内核分析
- C++ 内存管理
- C++ 的生前死后 - 揭秘 CRT Startup code
- C++2.0 新特性
0.0 目标
- 培养正规的、大气的编程习惯
- 以良好的方式编写 C++ Class —— 基于对象(Object Based)
- class without pointer members,以 Complex 为例子
- class with pointer members,以 String 为例子
- 学习 Classes 之间的关系 —— 面向对象(Object Oriented)
- 继承(inheritance)
- 组合(composition)
- 委托(delegation)
将 C++ 视为一个由相关语言组成的联邦
术语
- 声明(declaration):告诉编译器某个东西的名称和类型(type),但略去细节
- 定义(definition):提供编译器一些声明时所遗漏的细节。对对象而言,定义是编译器为此对象拨发内存的地点;对 function 或 function template 而言,定义提供了代码本体;对 class 或 class template 而言,定义列出了它们的成员
- 初始化(initialization):是“给予对象初值”的过程。对用户自定义类型的对象而言,初始化由构造函数执行。构造函数最好使用成员初值列(member initialization list),而不要在构造函数本体内使用赋值操作(assignment)。初值列列出的成员变量,其排列次序应该和它们在 class 中的声明次序相同
- default 构造函数:是一个可被调用而不带任何实参者,这样的构造函数要不没有,要不就是每个参数都有缺省值(默认值)
- 不明确行为(undefined):例如,
i++ + ++i,未定义行为,“有问题的,坏的行为,理论上什么事情都可能发生”,你无法稳定预估运行期会发生什么事 - 未指定行为(unspecified):例如,参数的求职顺序,“你不能依赖的某个特定顺序,但其行为是良好定义的”
- 实现定义的行为(implementation):例如,当一个 double 转换为 float 时,如果 double 变量的值不能精确表达在一个 float 中,那么选取下一个接近的离散值还是上一个接近的离散值是 implementation defined 的,实现定义的,“你可以在实现商的编译器文档中找到说明”
Header(头文件)中的防御式编程
#ifndef __LCOMPLEX__
#define __LCOMPLEX__
/**
0. 前置声明(forward declarations)
*/
class ostream;
class lcomplex;
lcomplex& __doapl(lcomplex* ths, const lcomplex& r);
/**
1. 类声明(class declarations)
需要思考:
- 复数应该具有哪些数据,提供哪些函数,才能够满足使用复数的用户的需求
*/
class lcomplex
{
//...
};
/**
2. 类定义(clss definition)
*/
lcomplex::function ...
#endif // __LCOMPLEX__
避免重复的 #include 头文件
inline 函数
- 函数如果太复杂,编译器就没法将其
inline - 函数若在
class body中定义完成,便自动成为inline候选者 inline标识符或者在class body中定义的函数只是对编译器的建议而已,是否真的inline是由编译器来决定的
构造函数 constructor
- 函数名跟类名相同
- 没有返回值类型,因为构造函数就是要来创建对象的,不用写
- 可以拥有参数
- 参数可以有默认值(其他函数的参数都可以有默认值)
- 构造函数有特殊的语法:初始值列(initialization list)
构造函数使用初值列(initialization list)进行会更好。这种写法相较于在函数体中进行赋值(assignments)有什么好处呢?性能上更优,写法更符合 C++ 规范
参见《Effective C++》条款 4:确定对象被使用前已先被初始化
将对象初始化,C++ 在某些语境下是保证会进行初始化的,但在其他语境下却不保证。读取未初始化的值会导致不明确的行为(undefined behavior)
最佳实践 Best Practice:永远在使用对象之前先将它初始化
- 对应无任何成员的内置类型,手动进行初始化,C++ 不保证初始化它们
- 对于用户自定义类型,初始化责任落在构造函数身上,确保每一个构造函数都将对象的每一个成员初始化。构造函数最好使用成员初值列(member initialization list),而不要在构造函数本体内使用赋值操作(assignment)。初值列列出的成员变量,其排列次序应该和它们在 class 中的声明次序相同
一个变量其数值的设定分两个阶段,1)初始化(对应构造函数 : 后的初值列),2)赋值(对应构造函数 {} 中的赋值操作)
区分赋值和初始化(assignment and initialization)
class PhoneNumber { ... };
class ABEntry {
public:
ABEntry(const std::string& name, const std::string& address,
const std::list<PhoneNumber>& phones);
private:
std::string theName;
std::string theAddress;
std::list<PhoneNumber> thePhones;
int numTimesConsulted;
};
ABEntry::ABEntry(const std::string& name, const std::string& address,
const std::list<PhoneNumber>& phones)
// 编译器会为用户自定义类型(user-defined types)之成员变量自动调用 default 构造函数
{
theName = name; // 这些都是赋值(assignments),而非初始化(initializations)
theAddress = address;
thePhones = phones;
numTimesConsulted = 0;
}
C++ 规定,对象的成员变量的初始化动作发生在进入构造函数本体之前。在 ABEntry 构造函数内,theName、theAddress 和 thePhones 都不是被初始化,而是被赋值。初始化的发生时间更早,发生于这些成员的 default 构造函数被自动调用之时(比进入 ABEntry 构造函数本体的时间更早)
ABEntry 构造函数的一个较佳写法是,使用成员初值列(member initalization list)替换赋值动作:
ABEntry::ABEntry(const std::string& name, const std::string& address,
const std::list<PhoneNumber>& phones)
: theName(name), // 这些都是初始化(initializations)
theAddress(address),
thePhones(phones),
numTimeConsulted(0)
{ }
- 基于赋值的版本,首先调用 default 构造函数为
theName、theAddress和thePhones设初值,然后立刻再对它们赋新值。default 构造函数的一切行为因此浪费了 - 基于成员初值列的版本,初值列针对各个成员变量设置实参,然后调用各个成员变量对应的拷贝构造函数
- 对于大多数类型而言,比起先调用 default 构造函数然后再调用 copy assignment 操作符,单只调用一次 copy 构造函数是比较高效的,有时甚至高效得多
- 对于内置类型对象如
numTimeConsulted,其初始化和赋值的成本相同,但为了一致性最好也通过成员初值列来初始化 - 如果成员变量是
const或referenece,它们就一定需要初值,不能被赋值 - 总是在初值列中列出所有成员变量,以免还得记住哪些成员变量可以无需初值
- 总是使用成员初值列
- C++ 的成员初始化次序:base classes 早于其 derived classses 被初始化,而 class 的成员变量总是已其声明次序被初始化。当在成员初值列中列出各个成员时,最好总是以其声明次序为次序
不同编译单元内定义的 non-local static 对象
参见《Effective C++》条款 4:确定对象被使用前已先被初始化
static 对象包括 global 对象、定义于 namespace 作用域内的对象、在 class 内、在函数内、以及在 file 作用域内被声明为 static 的对象。函数内的 static 对象成为 local static 对象(因为它们对函数而言是 local),其他 static 对象称为 non-local static 对象。程序结束时 static 对象会被自动销毁,也就是它们的析构函数会在 main() 结束时被自动调用
编译单元基本上就是单一源码文件加上其所 include 的头文件。考虑两个不同的源码文件,每一个文件内含有至少一个 non-local static 对象,也就是说该对象是 global 或位于 namespace 作用域内,抑或是在 class 内或在 file 作用域内被声明为 static。真正的问题是:如果某编译单元内的某个 non-local static 对象的初始化动作使用了另一个编译单元内的某个 non-local static 对象,它所用到的这个对象可能尚未被初始化,因为 C++ 对“定于于不同编译单元内的 non-local static 对象”的初始化次序并无明确定义
解决办法:将每个 non-local static 对象搬到自己的专属函数内(该对象在此函数内被声明为 static),这些函数返回一个 reference 指向它所含的对象,然后用户调用这些函数,而不直接指涉这些对象。换句话说,non-local static 对象被 local static 对象替换了。这是单例模式的一个常见实现手法。
这个手法的基础在于:C++ 保证,函数内的 local static 对象会在“该函数被调用期间”“首次遇上该对象之定义式”时被初始化。所以,以“函数调用”(返回一个 reference 指向 local static 对象)替换“直接访问 non-local static 对象”,就获得保证,保证了通过函数调用所获得的 reference 将指向一个历经初始化的对象
将构造函数放在 private 域,单例模式(Singleton)
class A {
public:
static A& getInstance() { return a; }
setup() { ... }
private:
A();
A(const A& rhs);
static A a;
...
};
class A {
public:
static A& getInstance();
setup() { ... }
private:
A();
A(const A& rhs);
...
};
// referen-returning 函数:第一行定义并初始化一个 local static 对象,第二行返回它
A& A::getInstance()
{
static A a; // 定义并初始化一个 local static 对象
return a; // 返回一个 reference 指向上述对象
}
之后使用 A::getInstance().setup(); 进行调用
const
参见《Effective C++》条款 3:尽可能使用 const
令函数返回一个常量值,往往可以降低因客户错误而造成的意外,而又不至于放弃安全性和高效性。例如,有理数的 operator* 声明式:
class Rational
{
//...
};
const Rational operator*(const Rational& lhs, const Rational& rhs);
避免出现以下的使用错误:
Rational a, b, c;
if (a * b = c) {
//...
}
编程时错误地将关系运算符 == 漏写为了赋值运算符 =。如果 a、b 是内置类型,这样的代码直截了当就是不合法。因此,我们在设计用户自定义类型时,应该避免无端地与内置类型不兼容,将 operator* 的返回值声明为 const 可以语法这个无意义的赋值动作
常量成员函数
在函数声明的参数列表右括号的后面添加 const 限制
class Complex
{
public:
double real();
double real() const;
void set_real(double r);
private:
double real;
};
class 里面的函数分为两种:
- 会改变对象中包含的数据内容;
- 不会改变对象中包含的数据内容,加上
const修饰
注意:
- 两个成员函数如果只是常量性(constness)不同(是否是常量成员函数),可以被重载(overloaded)
- C++ 以 by value 返回对象
成员函数如果是 const 意味着什么?const 成员函数不可以更改对象内任何 non-static 成员变量,也就是说不可以更改对象内的任何一个 bit。编译器强制实施 bitwise constness,但你编写程序时应该使用“概念上的常量性”(conceptual constness)
对成员函数,该使用 const 修饰的,一定要加 const 修饰。否则,创建一个 const 常量实例,然后调用这个未使用 const 修饰的成员函数(就是告诉编译器说该函数可能会改变对象包含的数据内容),而实例使用 const 修饰(就是告诉编译器说这个实例是常量,其包含的数据内容是不能被改变的),这样就出现了矛盾,编译器就会报错
参数传递 pass by value vs. pass by reference (to const)
- pass by value:value 数据多大,函数进行参数传递的时候就把整个包都一起传过去,压入函数栈里面去
- Best Practice:尽量不要 pass by value
- pass by reference,引用在底层的实现就相当于是指针,传引用就相当于传指针
- Best Practice:参数传递尽量传引用 reference-to-const;传递引用又不希望函数会对值进行修改,可以传递 reference to const
返回值传递 return by value vs. return by reference (to const)
- 返回值传递尽量 return by reference
什么情况下可以 pass by reference?什么情况下可以 return by reference?
一个函数的运算结果是放置在什么位置呢?
- 函数必须新创建一个地方来进行存放,函数需要返回新创建的这部分内容,但这部分内容的生命周期在函数调用返回时就结束了(函数调用栈释放了),为局部变量(local object),这时候就不能返回 reference,只能 return by value,在“临时对象”有示例;
- 放置在已存在的位置上,就可以 return by reference
临时对象
在类名后面直接加 ():typename (),临时对象 temp object
inline lcomplex
operator + (const lcomplex& x, const lcomplex& y) {
return lcomplex(real(x)+real(y), imag(x)+imag(y));
}
友元 friend
自由取得 friend 的 private 成员
相同 class 的各个 objects 互为友元
class lcomplex
{
public:
lcomplex(double r = 0, double i = 0)
: re(r), im(i) {}
int func(const lcomplex& param)
{ return param.re + param.im; }
private:
double re, im;
};
operator overloading 操作符重载
该选择成员函数,还是非成员函数?
成员函数
所有的成员函数都含有一个隐藏的参数 this 指针,谁调用这个成员函数,谁就是 this

对于 return by reference 语法,传递者无需知道接收者是以 reference 形式接收的
非成员函数(全域函数),无 this 指针
输入输出操作符重载
- 只能写成非成员函数
- 函数的第一个参数不能加
const,因为每次使用<<向os输出值的时候,os的状态都在改变 - 函数返回为
ostream&,支持连续输出
#include <iostream>
ostream&
perator << (ostream& os, const lcomplex& x) {
return os << '(' << real(x) << ',' << imag(x) << ')';
}
cout
class _IO_ostream_withassign : public ostream
{
// ...
};
extern _IO_ostream_withassign cout;
class ostream : virtual public ios
{
public:
ostream& operator<<(char c);
ostream& operator<<(unsigned char c) { return (*this) << (char)c; }
ostream& operator<<(signed char c) { return (*this) << (char)c; }
ostream& operator<<(const char* s);
ostream& operator<<(const unsigned char* s) { return (*this) << (const char*)s; }
ostream& operator<<(const signed char* s) { return (*this) << (const char*)s; }
ostream& operator<<(const void *p);
ostream& operator<<(int n);
ostream& operator<<(unsigned int n);
ostream& operator<<(long n);
ostream& operator<<(unsigned long n);
// ...
}
小结
设计一个类,怎么写才是更为规范的?
- 数据一定是放置在 private 里面的
- 参数尽可能使用 reference 传递,并且考虑是否使用 const 修饰
- 返回值尽可能使用 reference 传递
- 需要使用 const 修饰的成员函数就一定要使用 const 进行修饰,不然可能编译器会报错
- 构造函数使用 initialization list 进行初始化
Big Three 三个特殊函数
参见《Effective C++》条款 5:了解 C++ 默默编写并调用哪些函数
- 编译器会默认生成一套default 构造函数,拷贝构造函数和拷贝赋值函数,析构函数,都是
public修饰 - 编译器默认生成的会一个 bit 一个 bit 拷贝
- 需要考虑编译器默认生成的函数是否够用和适用
- 在 C++11 中,可以通过将拷贝构造函数和拷贝赋值函数定义为删除函数(delete function)来阻止拷贝,表明:我们虽然声明了它们,但不能以任何方式使用它们,直接在函数的参数列表后面加上
=delete来指定删除函数 - class with pointer members 必须要有拷贝构造函数和拷贝赋值函数,还需要有析构函数
- 在拷贝赋值函数开始部分一定要检查是否是自我赋值(self assignment),保证正确性和高效率
参见《Effective C++》条款 11:在 operator= 中处理“自我赋值”
- Best Practice最佳实践:大多数类应该定义默认构造函数、拷贝构造函数、拷贝赋值运算符和析构函数,无论是隐式地还是显式地
拷贝构造函数和拷贝赋值函数
参见《Effective C++》条款 12:复制对象时勿忘其每一个成分
为 derived class 编写拷贝构造函数和拷贝赋值函数,要确保(1)复制所有 local 成员变量,(2)调用所有 base classes 内的适当的 coping 函数
- 拷贝构造函数被用来“以同型对象初始化自我对象”
- 拷贝赋值函数被用来“从另一个同型对象中拷贝其值到自我对象”
- 如果一个新对象被定义,一定会有个构造函数被调用,不可能调用赋值操作。如果没有新对象被定义,就不会有构造函数被调用,那么就是拷贝赋值函数被调用
- 赋值符号
=也可以用来调用拷贝构造函数 - 拷贝构造函数定义了一个对象如何 pass-by-value(以值传递)
- 以 by-value 传递用户自定义类型通常是个坏主意,pass-by-reference-to-const 往往是比较好的选择
浅拷贝
深拷贝
何谓栈(stack),何谓堆(heap)
class Complex { /* ... */ };
/* ... */
Complex c3(1, 2);
{
Complex c1(1, 2);
static Complex c2(1, 2);
Complex* p = new Complex(3);
/* ... */
delete p;
}
- Stack,是存在于某个作用域(scope)的一块内存空间(memory space)
- Heap,或谓 System heap,是指操作系统提供的一块全局内存空间,程序可动态分配(dynamic allocated)从中获得若个区块(blocks)
生命周期
c1为 stack objects,其生命在作用域结束之际结束。这种作用域内的 object,又称为 auto object,因为它们会被自动清理,析构函数在作用域结束之际自动调用c2为 static local objects,其生命在作用域结束之后仍然存在,直到整个程序结束,即从被构造出来直到程序结束为止c3为 global objects,其生命在整个程序结束之后才结束。其作用域是整个程序p为 heap objects,其生命在它被 delete 之际结束
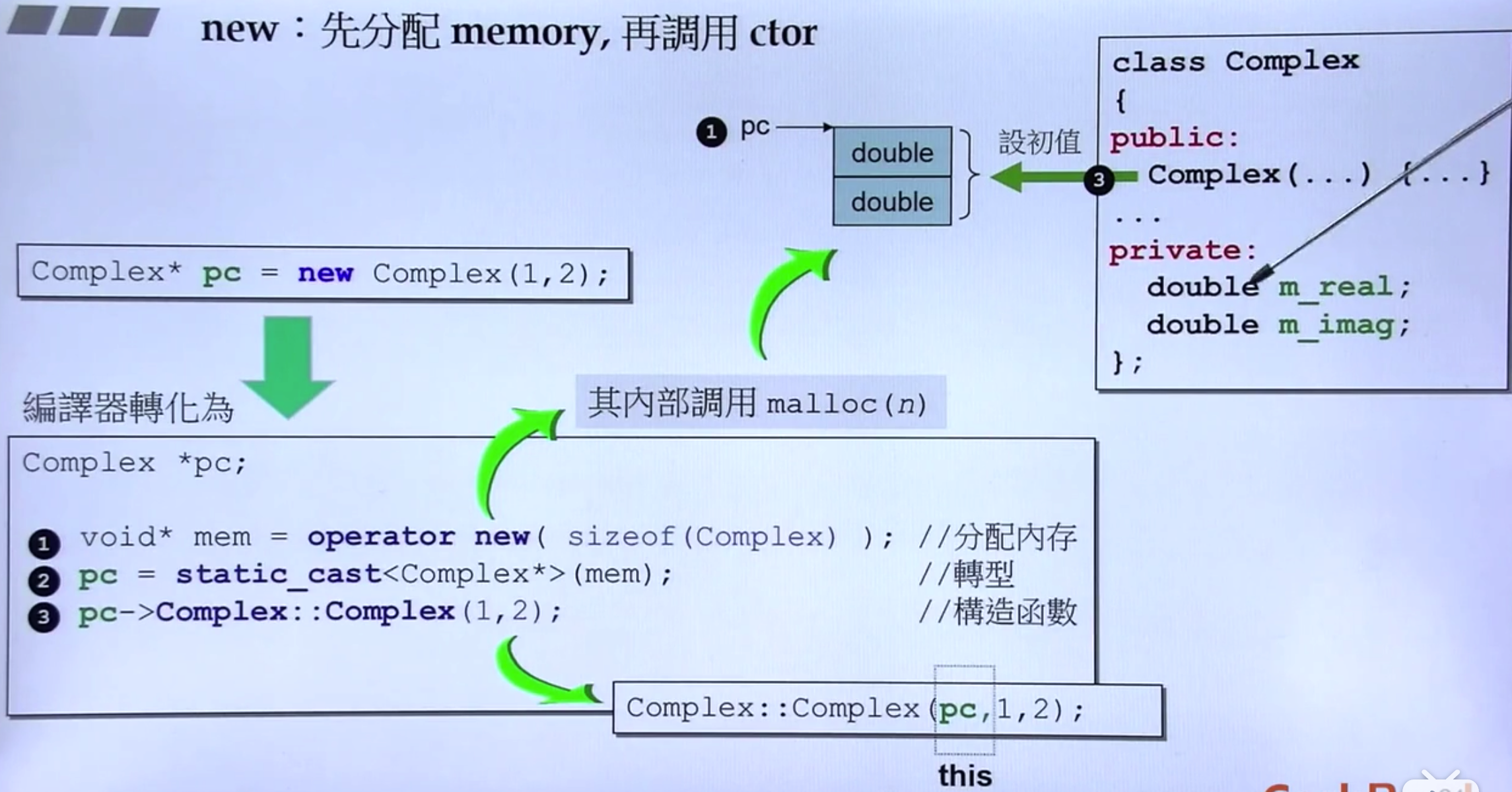
new 和 delete
参见《Effective C++》条款 16:成对使用 new 和 delete 时要采用相同形式
new
(1)内存被分配出来(通过名为 operator new 的函数);
(2)针对此内存会有一个(或多个)构造函数被调用
delete
(1)针对此内存会有一个(或更多)析构函数被调用;
(2)释放内存(通过名为 operator delete 的函数)
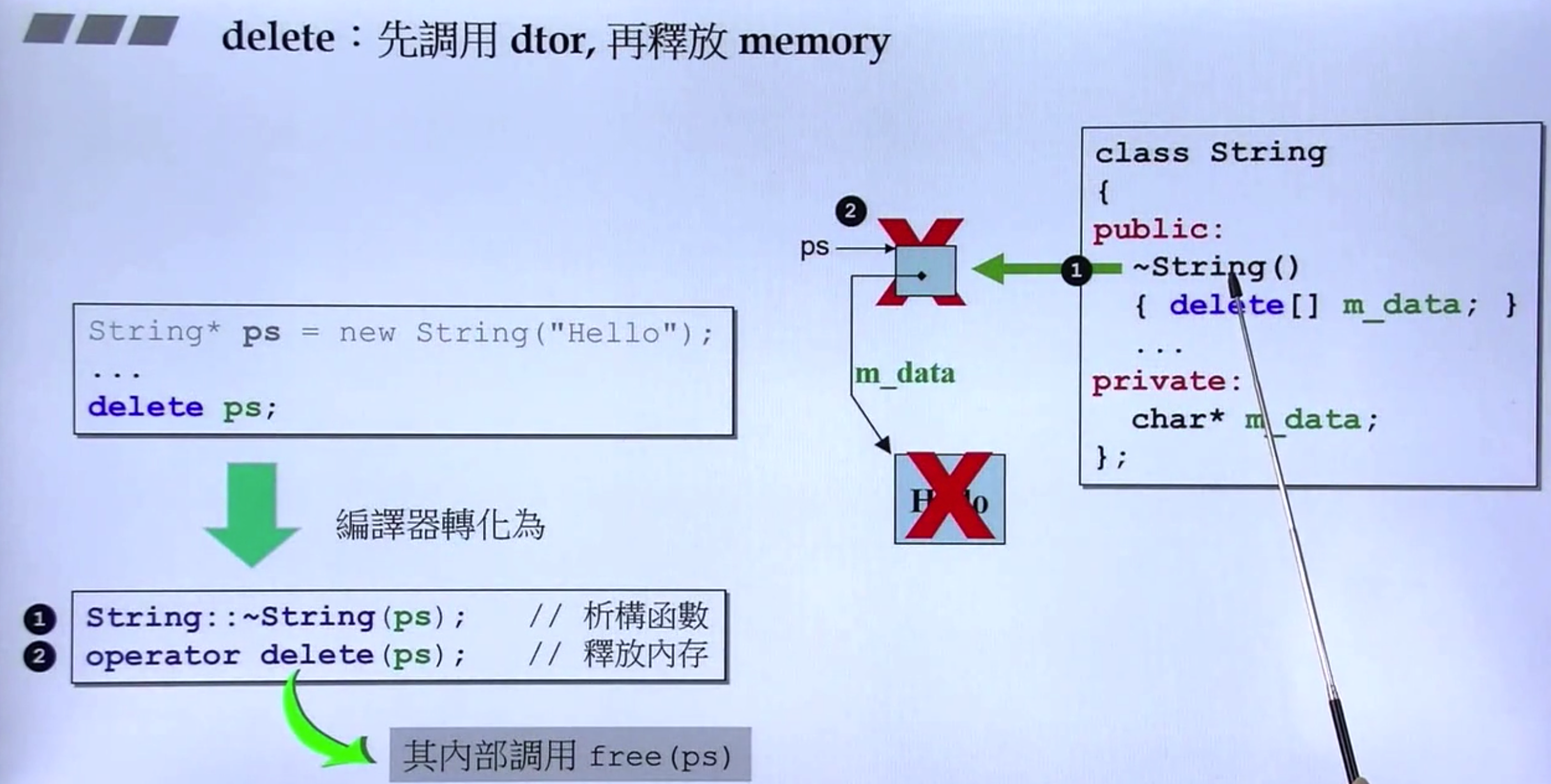
delete 的最大问题在于:即将被删除的内存之内究竟存有多少对象?这个问题决定了有多少个析构函数必须被调用起来。更简单的表述为:即将被删除的那个指针,所指的是单一对象还是对象数据?因为单一对象的内存布局一般而言不同于数组的内存布局。更明确地说,数组所用的内存通常还包括“数组大小”的记录,以便 delete 知道需要调用多少次析构函数。单一对象的内存则不需要这笔记录。
单一对象的内存布局示意图
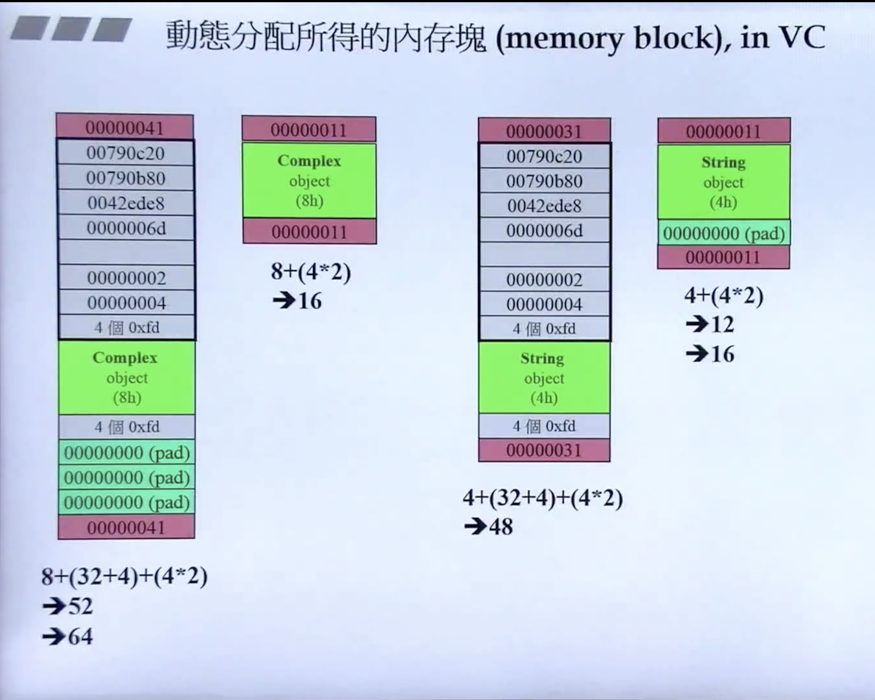
对象数组的内存布局示意图
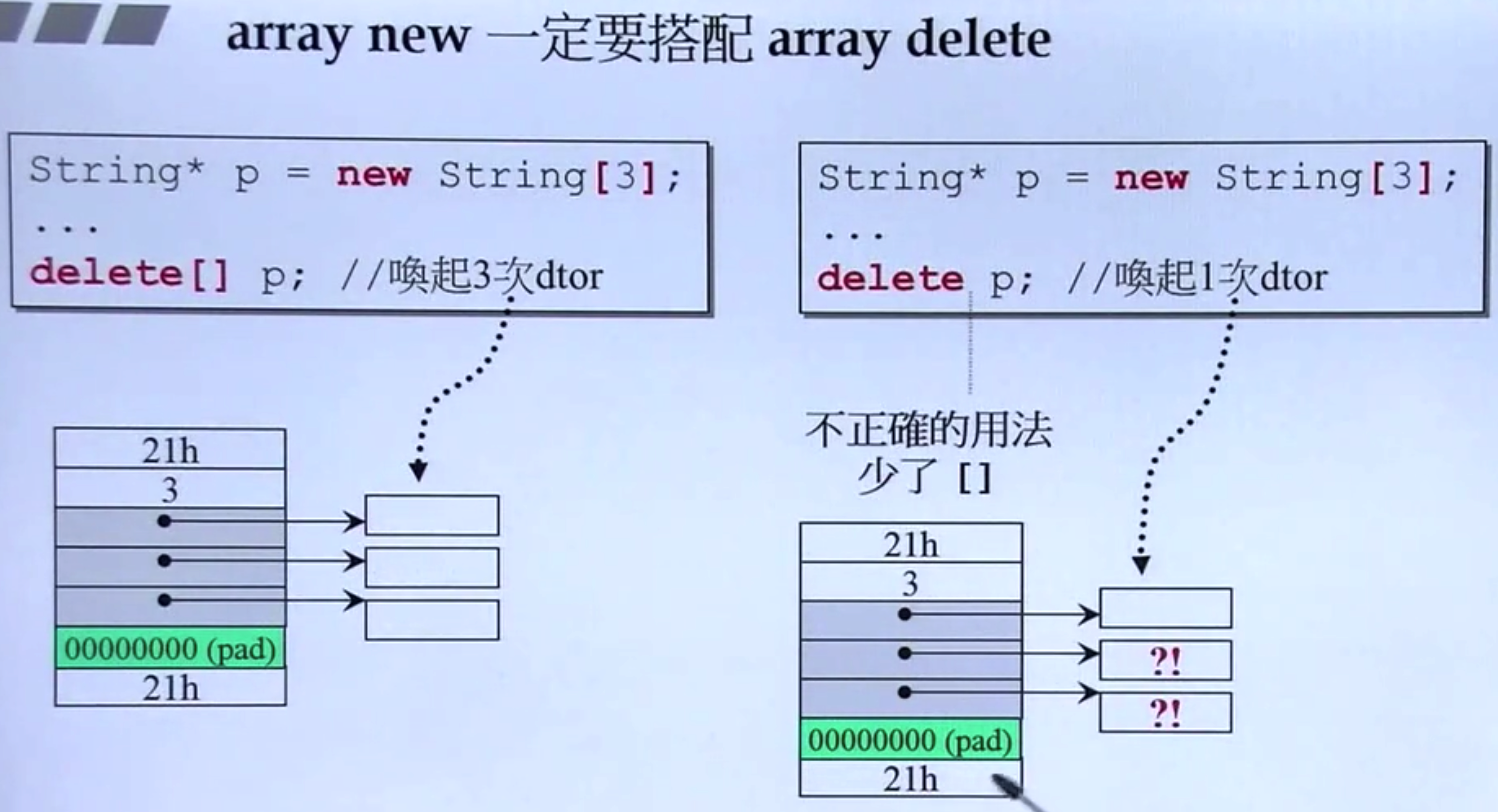
- array new 要搭配 array delete 使用,程序员需要告诉编译器需要
delete的“数组大小” - 如果调用
new时使用[],必须在对应调用delete时也使用[] - 如果调用
new时没有使用[],一定不要在对应调用delete时使用[]

static
- 静态成员函数没有 this 指针,因此只能处理静态数据
- 调用 static 函数的方式有两种:
- 通过 object 调用
- 通过 class name 调用
class Account
{
public:
static double m_rate; // 声明
static void set_rate(const double x) { m_rate = x; }
};
double Account::m_rate = 8.0; // 定义,使得对应的变量获得内存
int main(void)
{
Account::set_rate(5.0);
Account a;
a.set_rate(7.0);
}
利息 m_rate 称为 class 专属变量(class-specific variables):
- 为了将变量的作用域(scope)限制于 class 内,必须让它成为 class 的一个成员(member)
- 为了确保此变量至多只有一份实体,必须让它成为一个 static 成员
类模版 class template
template<typename T> // template、typename 都是关键字
class complex
{
public:
complex(T r = 0, T i = 0)
: re(r), im(i) {}
complex& operator+=(const complex&);
T real() const { return re; }
T imag() const { return im; }
private:
T re, im;
};
{
complex<double> c1(1.5, 3.5);
complex<int> c2;
...
}
函数模版 function template
- 编译器会做实参推导(argument deduction)
- C++ 标准库中的算法都是函数模版
namespace
namespace <namespace-name>
{
// ...
}
- using directive,
using namespace std; - using declaration,
using std::cout; - 每一项都是用全名
面向对象编程(面向对象设计)
类和类之间的关系:
- 继承 Inheritance
- 组合 Composition
- 委托 Delegation
Composition 复合,表示 has-a
template <class T, class Sequence = deque<T> >
class queue
{
// ...
protected:
Sequence c; // 底层容器
public:
// 以下完全利用 c 的操作函数完成
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference front() { return c.front(); }
reference back() { return c.back(); }
// deque 是两端可进出,queue 是末端进前端出,先进先出
void push(const value_type& x) { c.push_back(x); }
void pop() { c.pop_front(); }
};
- 学会使用 UML 类图来表示
- Adapter 设计模式
- Container 和 Component 的生命期一致
Composition 关系下的构造和析构
编译器帮助完成:
- 构造由内而外:Container 的构造函数首先调用 Component 的 default 构造函数,然后才执行自己
Container::Container(...): Component() { ... }
- 析构由外而内:Container 的析构函数函数首先执行自己,然后才调用 Component 的析构函数
Container::~Container(...): { ... ~Component(); }
Delegation 委托,Composition by reference
// file String.hpp
class StringRep;
class String
{
public:
String();
String(const char* s);
String(const String& s);
String& operator=(const String& s);
~String();
private:
StringRep* rep; // pimpl -> pointer to implementation, handle & body
};
// file String.cpp
#include "String.hpp"
namespace {
class StringRep {
friend class String;
StringRep(const char* s);
~StringRep();
int count;
char* rep;
};
}
String::String() { ... }
- 编译防火墙:Handle/Body,pImpl
- 引用计数(reference counting)
- COW(copy on write),当共享的变量需要改变内容时,先完全拷贝一份,然后在得到的拷贝上进行相应的修改
Inheritance 继承,表示 is-a
struct _List_node_base
{
_List_node_base* _M_next;
_List_node_base* _M_prev;
};
template<typename _Tp>
struct _List_node
: public _List_node_base
{
_Tp _M_data;
}
- 父类的数据会被子类完整继承
Inheritance(继承)关系下的构造和析构
参见《Effective C++》条款 7:为多态基类声明 virtual 析构函数
- 带多态性质的 base classes 应该声明一个 virtual 析构函数,这种 base classes 的设计目的是为了“通过 base class 接口处理 derived class 对象”。如果 class 带有任何 virtual 函数,它就应该拥有一个 virtual 析构函数
- classes 的设计目的不是作为 base classes 使用,或不是为了具备多态性,就不该声明 virtual 析构函数。例如标准 string 和 STL 容器都不被设计作为 base classes 使用
- 构造由内而外:Derived 的构造函数首先调用 Base 的 default 构造函数,然后才执行自己
Derived::Derived(...): Base() { ... };
- 析构由外而内:Derived 的析构函数首先执行自己,然后才调用 Base 的析构函数
Derived::~Derived(...) { ... ~Base() };
Inheritance(继承)with virtual function(虚函数)
在继承的关系下,父类所有的东西都会被子类继承
- 数据可以被继承下来,占用内存的一部分
- 函数也可以被继承下来,子类继承父类函数的调用权,子类可以调用父类的函数。那子类是否需要对继承的父类函数进行重新定义呢?
class Shape {
public:
virtual void draw() const = 0; // 1. 纯虚函数,pure virtual
virtual void error(const std::string& msg); // 2. 虚函数,impure virtual
int objectID() const; // 3. 普通函数
...
};
class Rectangle : public Shape { ... };
class Ellipse : public Shape { ... };
- pure virtual 函数:希望子类一定要重新定义(override,覆写)的函数,现在父类中没有默认定义(可以有定义)
- impure virtual 函数:希望子类重新定义(override,覆写)的函数,但父类中已提供了默认定义
- non-virtual 函数:不希望子类重新定义(override,覆写)的函数
- 创建子类对象
- 通过子类对象调用父类方法
- Template method 设计模式
Inheritance+Composition 关系下的构造和析构
Delegation(委托)+Inheritance(继承)
class Subject
{
int m_value;
std::vector<Observer*> m_views;
public:
void attach(Observer* obs) {
m_views.push_back(obs);
}
void set_val(int value) {
m_value = value;
notify();
}
void notify() {
for (int i = 0; i < m_views.size(); ++i) {
m_views[i]->update(this, m_value);
}
}
};
class Observer
{
public:
virtual void update(Subject* sub, int vaule) = 0;
}
- Observer 设计模式
- Composite 设计模式
- Prototype 设计模式:当下要去创建未来的 class 对象
参考书 Design Patterns Explained Simply
1.0 目标
- 在 0.0 的基础课程所培养的正规、大器的编程素养上,继续探讨更多技术
- 范型编程(Generic Programming)和面向对象编程(Object-Oriented Programming)虽然分属不同思维,但它们正是 C++ 的技术主线,本部分也讨论 template(模版)
- 深入探索面向对象之继承关系(inheritance)所形成的对象模型(Object Model),包括隐藏于底层的 this 指针,vptr(虚指针),vtbl(虚表),virtual mechanism(虚机制),以及虚函数(virtual function)造成的 Polymorphism(多态)效果
更多细节
- operator type() const;
- explicit complex(…) : initialization list {}
- pointer-like object
- function-like object
- Namespace
- template specialization
- Standard library
- variadic template (since C++11)–
- move ctor (since C++11)
- Rvalue reference (since C++11)
- auto (since C++11)–
- lambda (since C++11)
- range-base for loop (since C++11)–
- unordered containers (since C++11)
- …
conversion function 转换函数
- 将当前对象转换为别样的对象
class Fraction
{
public:
Fraction(int num, int den=1)
: m_numerator(num), m_denominator(den) {}
operator double() const {
return (double)(static_cast<double>(m_numerator) / static_cast<double>(m_denominator));
}
private:
int m_numerator; // 分子
int m_denominator; // 分母
};
{
Fraction f(3, 5);
double d = 4 + f;
std::cout << d << std::endl;
return 0;
}
在标准库中有如下源码:
vector bool
non-explicit-one-argument ctor
- one argument,只要一个实参就够了,另外可以有实参,提供对应的默认值即可
- two parameters, one argument
- 关键字 explicit,“明白的,明确的”,用在构造函数的前面,禁止编译器执行非预期的类型转换
- 将别种对象转换为当前对象
class Fraction
{
public:
Fraction(int num, int den=1)
: m_numerator(num), m_denominator(den) {}
Fraction operator+(const Fraction& f) {
return Fraction(this->m_numerator + f.m_numerator,
this->m_denominator + f.m_denominator);
}
private:
int m_numerator; // 分子
int m_denominator; // 分母
};
{
Fraction f(3, 5);
double d = 4 + f;
std::cout << d << std::endl;
return 0;
}
pointer-like classes
设计一个 class,让它的行为像一个指针
shared-ptr 关于智能指针
shared-ptr 持续追踪共有多少对象指向某笔资源,并在无人指向它时自动删除该资源。shared-ptr 允许指定所谓的“删除器(deleter)”,是一个函数或者函数对象(function object),当引用计数为 0 时便被调用
template<class T>
class shared_ptr
{
public:
T& operator*() const { return *px; }
T* operator->() const { return px; }
private:
T* px;
long* pn;
};
struct Foo
{
...
void method(void) { ... }
};
shared_ptr<Foo> sp(new Foo);
Foo f(*sp);
sp->method(); // px->method(), -> 会一直作用下去
- 智能指针里面包含有普通指针
*->运算符重载的写法确定,允许隐式转换至底层原始指针
参见《Effective C++》条款 13:以对象管理资源
“以对象管理资源”的两个关键想法:
- 获得资源后立刻放进管理对象内。实际上,“以资源管理对象”的观念常被称为“资源取得时机便是初始化时机”(Resource Acquisition Is Initialization,RAII),因为我们几乎总是在获得一笔资源后于同一语句内以它初始化某个管理对象,有时候获得的资源被拿来赋值某个管理对象(而非初始化)
- 管理对象运用析构函数确保资源被释放。不论控制流如何离开区块,一旦对象被销毁,其析构函数自然会被自动调用,于是资源被释放
iter 关于迭代器
template <class T>
struct __list_node
{
void* prev;
void* next;
T data;
};
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef __list_iterator<T, Ref, Ptr> self;
typedef Ptr pointer;
typedef Ref reference;
typedef __list_node<T>* link_type;
link_type node;
bool operator==(const self& x) const { return node == x.node; }
bool operator!=(const self& x) const { return node != x.node; }
reference operator*() const { return (*node).data; }
pointer operator->() const { return &(operator*()); }
self& operator++() { node = (link_type)((*node).next); return *this; }
self operator++(int) { self tmp = *this; ++*this; return tmp; }
self& operator--() { node = (link_type)((*node).prev); return *this; }
self operator--(int) { self tmp = *this; --*this; return tmp; }
};
{
list<Foo>::iterator ite;
...
*ite; // 获得一个 Foo object
ite->method(); // 意思是调用 Foo::method() 相当于 (*ite).method(); 相当于 (&(*ite))->method();
}
关于迭代器的补充说明:
STL 迭代器以指针为根据塑模出来,所以迭代器的作用就像个 T* 指针。声明迭代器为 const 就像声明指针为 const 一样(即声明一个 T* const 指针,指针本身是常量,但指向的值可以改变),表示这个迭代器不得指向不同的东西,但它所指的东西的值是可以改动的。如果希望迭代器所指的东西不可被改动(即希望 STL 模拟一个 const T* 指针),需要使用 const_iterator
std::vector<int> vec;
...
const std::vector<int>::iterator iter = vec.begin(); // iter 的作用像个 T* const
*iter = 10; // 没问题,可以改变 iter 所指物
++iter; // 错误!iter 是 const
std::vector<int>::const_iterator cIter = vec.cbegin(); // cIter 的作用像个 const T*
*cIter = 10; // 错误!*cIter 是 const
++cIter; // 没问题,可以改变 cIter
function-like classes 所谓仿函数
设计一个 class,让它的行为像一个函数
思考:C++ 为什么要让一个 Class 像一个指针或者像一个函数?在什么情景下?有什么好处?
()小括号,函数调用操作符(function-call operator)- 任何一个东西如果它能够接受
()操作符,我们就称这个东西是函数或者是一个像函数的东西 - 函数对象,仿函数
template <class T1, class T2>
struct Pair
{
T1 first;
T2 second;
Pair() : first(T1()), second(T2()) { }
Pair(const T1& a, const T2& b)
: first(a), second(b) { }
};
template <class T>
struct identity : public unary_function<T, T>
{
const T& operator()(const T& x) const { return x; }
};
template<class Pair>
struct select1st : public unary_function<Pair, typename Pair::first_type>
{
const typename Pair::first_type& operator()(const Pair& x) const { return x.first; }
};
template <class Pair>
struct select2nd : public unary_function<Pair, typename Pair::second_type>
{
const typename Pair::second_type& operator()(const Pair& x) const { return x.second; }
};
{
select1st<Pair>()()
// 1. 创建临时对象
// 2. 调用函数
}
标准库还有其他的仿函数
template <class T>
struct plus : public binary_function<T, T, T>
{
T operator()(const T& x, const T& y) const { return x + y; }
};
template <class T>
struct minus : public binary_function<T, T, T>
{
T operator()(const T& x, const T& y) const { return x - y; }
};
template <class T>
struct equal_to : public binary_function<T, T, bool>
{
bool operator()(const T& x, const T& y) const { return x == y; }
};
template <class T>
struct less : public binary_function<T, T, bool>
{
bool operator()(const T& x, const T& y) const { return x < y; }
};
- unary 一元运算符,一个操作数
- binary 二元运算符,两个操作数
标准库中,仿函数所使用的奇特的 base classes
template <class Arg, class Result>
struct unary_function
{
typedef Arg argument_type;
typedef Result result_type;
};
template <class Arg1, class Arg2, class Result>
struct binary_function
{
typedef Arg1 first_argument_type;
typedef Arg2 second_argument_type;
typedef Result result_type;
};
- sizeof(xxx) 理论上是 0,实际是 1
template 模版
class template 类模版
template <typename>
class complex
{
public:
complex(T r = 0, T i = 0)
: re(r), im(i) { }
complex& operator+=(const complex&);
T real() const { return re; }
T imag() const { return im; }
private:
T re, im;
};
{
complex<double> c1(2.5, 3.2);
complex<int> c2(2, 6);
}
function template 函数模版
class stone
{
public:
stone() : _w(0), _h(0), _weight(0) { }
stone(int w, int h, int we)
: _w(w), _h(h), _weight(we) { }
bool operator<(const stone& rhs) const { return _weight < rhs._weight; }
private:
int _w, _h, _weight;
};
template <class T>
inline const T& min(const T& a, const T& b)
{
return b < a ? b : a;
}
{
stone r1(1, 2, 3), r2(3, 3, 4), r3;
r3 = min(r1, r2);
}
- 编译器会对函数模版进行实参推导(argument deduction)
- 根据实参推导的结构,T 是
stone,于是调用stone::operator<
member template 成员模版
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 seconde_type;
T1 first;
T2 second;
pair()
: first(T1()), second(T2()) {}
pair(const T1& a, const T2& b)
: first(a), second(b) {}
// 成员模版
template <class U1, class U2>
pair(const pair<U1, U2>& p)
: first(p.first), second(p.second) {}
};
- 成员模版是 class template 里面的一个 member,然后它是一个模版,就称为 member template
- T1 T2是可以变换的,在 T1 T2 确定下来之后,里面的 U1 U2 也可以变化
- 为了让构造函数更有弹性
template <typename _Tp>
class shared_ptr : public __shared_ptr<_Tp>
{
...
template <typename _Tp1>
explicit shared_ptr(_Tp1* __p)
: __shared_ptr<_Tp>(__p) { }
...
};
Base1* ptr = new Derived1; // up-cast
shared_ptr<Base1> sptr(new Derived1); // 模拟 up-cast
specialization 模版特化
- 泛化 - 特化
- 在设计了一个模版之后,需要局部特化
// 泛化
template <class Key>
struct hash { };
// 特化
template <>
struct hash<char>
{
size_t operator()(char x) const { return x; }
};
template <>
struct hash<int>
{
size_t operator()(int x) const { return x; }
};
template <>
struct hash<long>
{
size_t operator()(long x) const { return x; }
};
- 泛化称为全泛化(full)
- 偏特化(partial specialization)
partial specialization 偏特化
个数上的偏
- bool 只需要占用一个 bit 上就可以了
template <typename T, typename Alloc=......>
class vector
{
...
};
template <typename Alloc=......>
class vector<bool, Alloc>
{
...
};
范围上的偏
template <typename T>
class C
{
// 类型不为指针,就使用这一套代码
...
};
template <typename U>
class C<U*>
{
// 类型为指针,就使用这一套特化代码
...
};
{
C<string> obj1; // 使用第一套代码
C<string*> obj2; // 使用第二套代码
}
- 接收任意类型
- 接收指针类型,指针也是任意类型中的一种
template template parameter 模版模版参数
template <typename T,
template <typename T>
class Container
>
class XCls
{
private:
Container<T> c;
public:
...
};
template <typename T>
using Lst = List<T, allocator<T>>;
XCls<string, list> mylist1; // error
XCls<string, Lst> mylist2; // success
template <typename T> class Container是一个模版的参数,其本身就是作为一个模版存在的- 在模版参数列表中,即尖括号中,
class和typename关键字是共通的。历史因素
template <typename T,
template <typename T>
class SmartPtr
>
class XCls
{
private:
SmartPtr<T> sp;
public:
XCls() : sp(new T) {}
};
XCls<string, shared_ptr> p1; // success
XCls<double, unique_ptr> p2; // error
XCls<int, weak_ptr> p3; // error
XCls<long, auto_ptr> p4; // success
这不是模版模版参数
template <class T, class Sequence = deque<T>>
class stack
{
friend bool operator== <> (const stack&, const stack&);
friend bool operator< <> (const stack&, const stack&);
protected:
Sequence c; // 底层容器
...
};
stack<int> s1;
stack<int, list<int>> s2;
C++ 标准库
库很重要,要熟用,掌握【侯捷另有一门讲 STL 标准库的视频课程】
确定当前编译器是否支持 C++11:macro __cplusplus
#include <iostream>
int main(void)
{
std::cout << __cplusplus << std::endl;
// - 对于支持 C++11 的编译器,输出为 201103,可能更高 C++20?
// - 对于 C++98 C++03,输出为 199711
return 0;
}
C++11:variadic template 数量不定的模版参数
void print()
{
}
template <typename T, typename... Types>
void print(const T& firstArg, const Types&... args)
{
cout << firstArg << endl;
print(args...);
}
- Inside variadic templates, sizeof…(args) yields the number of arguments
- 一个和一包(pack)
- 后面的一包可以拿来继承,组合
- 标准库中大量使用这个语法
C++11: auto
list<string> c;
...
// 1. 第一种用法
list<string>::iterator ite1;
ite1 = find(c.begin(), c.end(), target);
// 2. 第二种用法,编译器自动进行推断
auto ite2 = find(c.begin(), c.end(), target);
// 错误写法
auto ite3;
ite3 = find(c.begin(), c.end(), target);
C++11: range-base for loop
vector<double> vec;
...
for (auto elem : vec) { // pass by value
cout << elem << endl;
}
for (auto& elem : vec) { // pass by reference
elem * = 3;
}
- reference 引用的底层实现就是 pointer 指针,只是表现的形式不同,编译器都是使用指针来实现引用的
Reference 引用
从内存的角度去看变量,变量有三种
- 值 value 本身
- 指针,“指向”
- 引用,“代表”,一定要设置初值,设置完成之后不能改变
int x = 0;
int* p = &x;
int& r = x;
- sizeof(x) == sizeof(r)
- &x = &r
- reference 是一种漂亮的 pointer
编译器制造了一种假象,object 和其 reference 的大小相同,地址也相同
reference 的常见用途 – 参数传递
void func1(Cls* pobj) { pobj->xxx(); }
void func2(Cls obj) { obj.xxx(); }
void func3(Cls& obj) { obj.xxx(); } // func2 和 func3 调用端写法相同,很好
...
Cls obj;
func1(&obj); // 接口不同,困扰
func2(obj);
func3(obj); // func2 fun3 调用端接口相同,很好
reference 通常不用于声明变量,而用于参数类型(parameters type)和返回类型(return type)的描述
以下被认为是“same signature”(所以二者不能同时存在):
double imag(const double& im) { ... } // 传引用
double imag(const double im) { ... } // 传值,二者签名相同,Ambiguity
- 成员函数加 const 是不是函数签名的一部分?是签名的一部分!
版权声明
本作品采用知识共享署名 4.0 国际许可协议进行许可,转载时请注明原文链接。